Jak można korzystać z narzędzi generatywnej AI podczas pracy badawczej?
Do czego naukowcy mogą wykorzystać generatywną AI?
Oto kilka przykładów:
-
Tworzenie i debugowanie kodu: Generatywna AI może pomóc w pisaniu i poprawianiu kodu używanego do analizy statystycznej, tworzenia wizualizacji danych czy budowania stron internetowych prezentujących wyniki badań.
-
Kwestionowanie założeń: Pracując nad formułowaniem problemu badawczego, naukowcy mogą obsadzić generatywną AI w roli krytycznego dyskutanta, prosząc o wskazanie potencjalnych luk w badaniu lub pomoc w wyjściu poza utarte metodologiczne schematy.
- Generowanie danych syntetycznych: Generatywna AI może tworzyć syntetyczne dane odwzorowujące cechy danych rzeczywistych, co pozwala na wzbogacanie zbiorów treningowych lub testowanie metodologii przed zebraniem kosztownych danych rzeczywistych.
- Wspomaganie przeglądów literatury: Dzięki zdolnościom przetwarzania języka naturalnego, generatywna AI może wydobywać kluczowe informacje z artykułów naukowych, takie jak zależności między zmiennymi, hipotezy czy dane o próbie badawczej. Odpowiednio skonstruowane zapytania mogą zmniejszyć ryzyko halucynacji modelu, ograniczając jego odpowiedzi do treści zawartych w analizowanych artykułach.
Poza typowymi zastosowaniami narzędzi generatywnej AI, można wyróżnić dwa główne sposoby ich wykorzystania w pracy badawczej:
-
Generatywna AI jako narzędzie do przetwarzania tekstu: obejmuje zadania takie jak klasyfikacja, rozpoznawanie określonych jednostek (Named Entity Recognition), wyszukiwanie informacji (information retrieval) oraz rozstrzyganie wieloznaczności.
-
Generatywna AI do automatyzacji procesów i personalizacji narzędzi badawczych: usprawnia procesy badawcze oraz umożliwia dostosowywanie narzędzi do indywidualnych potrzeb badacza.
Generatywna AI jako narzędzie do przetwarzania tekstu
Generatywna AI jest rozwinięciem „przedgeneratywnych” metod przetwarzania języka naturalnego (NLP) i może być wykorzystywana do klasyfikacji tekstów. Liga i Robaldo (2023) pokazali, że nawet modele o stosunkowo ograniczonych możliwościach, takie jak GPT-3, po przeszkoleniu na specjalistycznych danych, lepiej radzą sobie z klasyfikacją tekstów prawniczych pod kątem zawartych w nich klauzul niż wcześniejsze modele NLP. Generatywna AI przewyższa starsze metody zwłaszcza w zadaniach, które wymagają zrozumienia subtelnych niuansów semantycznych. Jednak w przypadku klasyfikacji bazującej na występowaniu określonych słów kluczowych tradycyjne algorytmy klasyfikacyjne, przy odpowiednich zbiorach treningowych, nadal są wystarczające.
Co ciekawe, nawet w zadaniach, które nie wymagają zrozumienia złożonego kontekstu, takich jak Named Entity Recognition (NER) — czyli rozpoznawanie określonych jednostek w tekście, np. nazw białek czy genów — generatywna AI dorównuje, a często przewyższa wcześniejsze modele NLP pod względem skuteczności. Starszy model GPT-3 osiągał wyniki porównywalne z w pełni nadzorowanymi modelami NER (Wang i in., 2023). Wykazano również przydatność dużych modeli językowych w zastosowaniach NER do analizy tekstów z obszaru astronomii (Shao i in. 2023).
LLM, czyli duże modele językowe, możemy również z powodzeniem wykorzystać do rozstrzygania wieloznaczności (disambiguation). LLM można na przykład wykorzystać do analizy nieustrukturyzowanych profili internetowych osób noszących te same imiona i nazwiska (Sancheti i in., 2024).
Ważnym elementem modeli LLM są modele embeddingowe, które pozwalają na kodowanie informacji o znaczeniu jednostek tekstowych — od pojedynczych tokenów, przez zdania, aż po całe teksty. Embeddingi to wielowymiarowe wektory, co umożliwia wykonywanie operacji algebraicznych i określanie relacji między nimi, w tym podobieństw. Coraz bardziej zaawansowane modele embeddingowe, które lepiej uchwytują niuanse semantyczne dzięki większej liczbie wymiarów, odegrają istotną rolę w automatyzacji pracy analitycznej, pozwalając na bardziej precyzyjne wnioskowanie i analizę.
Przykładem zastosowania modeli embeddingowych jest tworzenie przejściówek (crosswalks) między różnymi klasyfikacjami. W ekonomii rynku pracy często wykorzystuje się przejściówki między amerykańską klasyfikacją ONET-SOC a europejską ISCO. Tradycyjnie proces ten jest czasochłonny, wymaga szczegółowej uwagi, tworzenia reguł i jest kosztowny, ponieważ musi być powtarzany przy każdej aktualizacji baz danych. Obecnie modele embeddingowe umożliwiają skuteczne dopasowanie klasyfikacji na podstawie samych nazw zawodów, a wzbogacenie modelu o dodatkowy kontekst, taki jak zadania czy opisy zawodów, pozwala na jeszcze precyzyjniejsze dopasowanie.
Cechą charakterystyczną wspomnianych zastosowań jest ograniczenie funkcji generatywnych LLM oraz oparcie się na wiedzy pochodzącej z określonych źródeł dostarczonych przez badacza (np. zbioru artykułów naukowych), zamiast na wiedzy z pierwotnego treningu modelu. Funkcje generatywne odnoszą się do zdolności modelu do tworzenia nowych treści bez powoływania się na konkretne źródła. Ograniczenie tych funkcji ma na celu zminimalizowanie problemu tzw. halucynacji, czyli generowania błędnych lub nieistniejących informacji.
Zaletą LLM w pracy badawczej, co wynika zarówno z naszych doświadczeń, jak i przeglądu literatury, jest przede wszystkim zdolność tych modeli do rozumienia języka naturalnego w kontekście zadanego przez badacza tekstu. Często, choć nie zawsze, jest to możliwe dzięki fine-tuningowi, czyli dostrajaniu wstępnie wytrenowanego modelu do specyficznych zadań lub obszarów tematycznych poprzez dodatkowy trening na mniejszych, dedykowanych zbiorach danych. Dzięki temu model lepiej radzi sobie z zadaniami wymagającymi wiedzy specjalistycznej.
Kolejną zaletą zastosowania LLM jest obniżenie progu wejścia do analiz NLP, ponieważ badacze mogą coraz częściej korzystać z modeli LLM w trybie zero-shot, czyli bez konieczności użycia zbiorów treningowych. Mimo braku specjalistycznej wiedzy z zakresu NLP i bez potrzeby pozyskiwania lub tworzenia dedykowanych zbiorów danych, można osiągać wyniki porównywalne do tych uzyskiwanych przy bardziej zaawansowanych metodach.
Generatywna AI do automatyzacji procesów i personalizacji narzędzi badawczych
Drugie zastosowanie generatywnej AI w pracy badawczej wykracza poza zastępowanie starszych modeli NLP. W tym podejściu generatywna AI służy do częściowej automatyzacji procesów badawczych oraz personalizacji narzędzi badawczych.
Fakt, że LLM są trenowane m.in. na literaturze naukowej, skłonił wielu badaczy do zbadania ich potencjału w tworzeniu przeglądów literatury. Naukowcy zaczęli sprawdzać wiedzę modeli w dobrze sobie znanych obszarach oraz wykorzystywać je do automatyzacji przeglądów literatury w dziedzinach, z którymi nie mieli wcześniej styczności. Ku ich zaskoczeniu, modele często "halucynowały", tworząc nieistniejące prace naukowe, rzekomo autorstwa znanych badaczy, z przekonująco brzmiącymi tytułami. Choć te błędy wynikają z procesu trenowania LLM i ich niewłaściwego wykorzystania, brak odpowiednich polityk informacyjnych lub możliwości blokowania generowania fałszywych odniesień, tak jak blokuje się treści dyskryminacyjne, obniża zaufanie naukowców do wykorzystywania LLM w pracy badawczej.
W odpowiedzi na niedoskonałości ogólnych narzędzi LLM w przeglądzie literatury naukowej trwają prace nad tworzeniem wyspecjalizowanych modeli. Modele te opierają się na zbiorach artykułów naukowych, które są strukturyzowane za pomocą narzędzi LLM, takich jak identyfikacja hipotez, wyników i innych kluczowych elementów. Następnie modele językowe są dostrajane (fine-tuning) do tych danych, a także opracowywane są specjalne prompty umożliwiające efektywne wydobywanie informacji z tekstów (Cao i in., 2024). Takie podejście pozwala modelom nie tylko lepiej rozumieć treść artykułów, ale także dostarczać kontekstu, w jakim autorzy uzyskali określone wyniki, oraz wskazywać, czy wyniki te potwierdzają lub obalają daną hipotezę. W efekcie wyspecjalizowane modele LLM stają się znacznie bardziej efektywne i precyzyjne w przeglądzie literatury naukowej (Nicholson i in., 2021).
Najlepsze modele LLM do przeglądów literatury są często kosztowne (np. scite_ kosztuje dla instytucji od 5000 USD rocznie, a dla studentów i indywidualnych badaczy około 50 zł miesięcznie). Wynika to z wysokich kosztów związanych z ich trenowaniem oraz tworzeniem baz danych, które opierają się na milionach artykułów, często ukrytych za paywallem. Warto jednak zauważyć, że rozwój tych zaawansowanych modeli w pewnym stopniu stoi w sprzeczności z ideą otwartej nauki (open science) i demokratyzacji wiedzy. Ograniczony dostęp do najbardziej zaawansowanych narzędzi może utrudniać upowszechnianie wiedzy i kłóci się z założeniami modelu otwartej nauki.
Rozwój modeli do przeglądów literatury ogranicza problem halucynacji, jednak nadal mamy do czynienia z wyzwaniem ich funkcjonowania jako tzw. czarne skrzynki (black boxes). Możliwe, że ruch przejrzystej AI (explainable AI) przyczyni się do większej przejrzystości w doborze literatury i kryteriach oceny (Xu i in., 2019). Na ten moment jednak zalecamy traktowanie tych narzędzi wyłącznie jako wsparcie w procesie przeglądu literatury, a nie jego główną podstawę.
Z kolei narzędzia LLM są przydatne w analizie artykułów wybranych w tradycyjnym przeglądzie literatury, opartym na słowach kluczowych. Wstępne wyniki badań prowadzonych przez DELab UW w ramach projektu IDUB UW wskazują na skuteczność modeli LLM w strukturyzowaniu informacji z artykułów naukowych, co wspiera prowadzenie systematycznych przeglądów literatury i metaanaliz.
Reprodukcja metaanalizy opublikowanej w prestiżowym czasopiśmie wykazała przewagę narzędzia text miningowego, stworzonego przez DELab UW i opartego na modelu GPT-4, nad pracą ludzkich adnotatorów. W przypadkach rozbieżności między wynikami modelu a ludzkimi, przewaga modelu prawdopodobnie wynikała z heurystyk stosowanych przez ludzkich asystentów podczas analizy dużych zbiorów artykułów. Zadanie polegało na wyodrębnieniu informacji dotyczących prób badawczych, głównych wyników, hipotez itp. Narzędzie text miningowe lepiej identyfikowało m.in. liczebność ostatecznej próby badawczej wykorzystanej w analizie.
Wstępne wyniki wskazują, że narzędzia LLM mają duży potencjał w czasochłonnych procesach, takich jak przygotowanie danych do metaanaliz. Umożliwiają one realizację tych zadań bardziej efektywnie kosztowo, eliminując potrzebę szkolenia asystentów badawczych do adnotacji tekstów i angażując ich raczej do oceny jakości pracy modelu. Kluczową zaletą modeli LLM jest ich skalowalność, dzięki której mogą analizować znacznie większą liczbę tekstów niż człowiek, co pozwala uwzględnić szerszy zakres literatury w badaniach.
Przykładem personalizacji narzędzi badawczych jest praca Paliński i in. (w przygotowaniu), w której autorzy wykorzystali model GPT-3.5 do tworzenia spersonalizowanych reklam w badaniu preferencji konsumentów dotyczących prywatności w kontekście usług streamingowych. Autorzy opracowali narzędzie przypominające popularną aplikację streamingową, z którą respondenci wchodzili w interakcję. Zbierane dane były następnie wykorzystywane w zapytaniach (promptach) do modelu GPT-3.5, który generował treści spersonalizowanych reklam wyświetlanych uczestnikom w formie animacji.
Rys. Schemat tworzenia narzędzia badawczego w oparciu o LLM - personalizacja reklam wyświetlanych respondentom w badaniu preferencji wobec personalizacji.
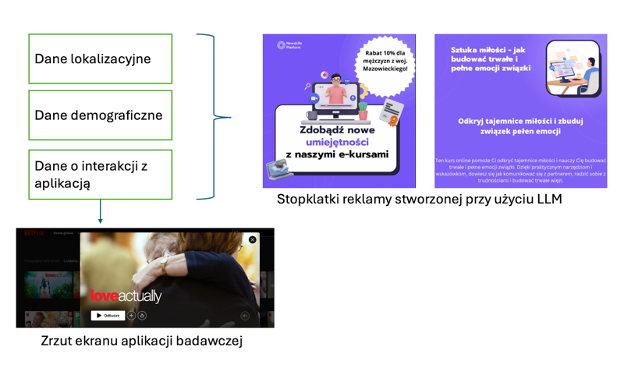
Źródło: Paliński i in. (w przygotowaniu).
Źródła:
Cao, C., Yuan, Z., & Chen, H. (2024). ScholarGPT: Fine-tuning Large Language Models for Discipline-Specific Academic Paper Writing.
Liga, D., & Robaldo, L. (2023). Fine-tuning GPT-3 for legal rule classification. Computer Law & Security Review, 51, 105864.
Nicholson, J. M., Mordaunt, M., Lopez, P., Uppala, A., Rosati, D., Rodrigues, N. P., ... & Rife, S. C. (2021). scite: A smart citation index that displays the context of citations and classifies their intent using deep learning. Quantitative Science Studies, 2(3), 882-898.
Paliński, M., Jusypenko, B., Hardy, W. (w przygotowaniu). Behind the Screens. Privacy concerns and persuasion knowledge as determinants of preferences for privacy and advertising on Netflix.
Sancheti, P., Karlapalem, K., & Vemuri, K. (2024). LLM Driven Web Profile Extraction for Identical Names. In Companion Proceedings of the ACM on Web Conference 2024 (pp. 1616-1625).
Shao, W., Hu, Y., Ji, P., Yan, X., Fan, D., & Zhang, R. (2023). Prompt-NER: Zero-shot named entity recognition in astronomy literature via large language models. arXiv preprint arXiv:2310.17892.
Wang, Shuang, Xiaoxu Sun, Xin Li, Renjie Ouyang, Fangxiang Wu, Tingting Zhang, and Guoxin Wang. (2023). “GPT-NER: Named Entity Recognition via Large Language Models.” arXiv preprint arXiv:2304.10428.
Xu, Feiyu, et al. "Explainable AI: A brief survey on history, research areas, approaches and challenges." Natural language processing and Chinese computing: 8th cCF international conference, NLPCC 2019, dunhuang, China, October 9–14, 2019, proceedings, part II 8. Springer International Publishing, 2019.
Zhou, Wenxuan, Sheng Zhang, Yu Gu, Muhao Chen, and Hoifung Poon. (2023). “Universalner: Targeted Distillation from Large Language Models for Open Named Entity Recognition.” arXiv preprint arXiv:2308.03279.