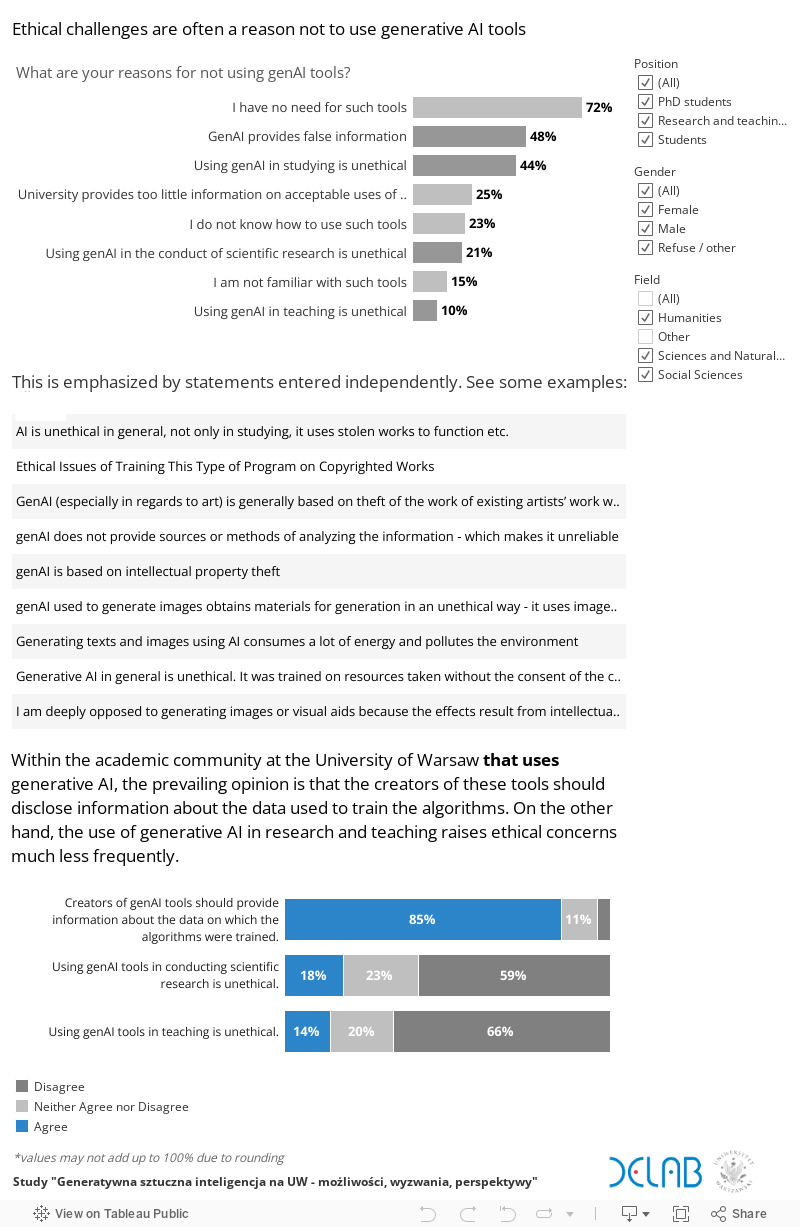
Ethical Issues Associated with Generative AI Tools
Selected examples of ethical challenges related to AI include:
-
the ease of creating manipulated materialsthat look authentic (deepfake). As the quality of such content increases, making it more difficult to distinguish between real images and videos from those generated by algorithms, developing critical thinking skills and source verification among students becomes increasingly important. The Artificial Intelligence Act introduces obligations to label content such as deepfakes (see Article 50: Transparency Obligations for Providers and Deployers of Certain AI Systems). Considering the time required for full implementation of the regulation and the uncertainty about the effectiveness of these regulations, the development of content verification skills becomes crucial.
-
algorithmic bias and discrimination. The obligation to maintain data representativeness, introduced in the Artificial Intelligence Act, may contribute to the development of algorithms that better address these issues. Nevertheless, the awareness that generative AI can replicate discriminatory patterns present in historical data should alert us to the risk of erroneous judgments suggested by these systems. Therefore, decisions or assessments should not be based solely on the results suggested by algorithms.
-
challenges regarding intellectual property protection, especially copyright. Although the outcomes of high-profile cases brought against OpenAI by artists and publishers are still unknown, the mere fact of harvesting content from the internet for developing commercial tools raises both ethical and legal concerns.
This last issue, in particular, may pertain to academic staff:
- Firstly, it relates to independently developing AI tools for research purposes, i.e., creating algorithms used in non-commercial research. There are some solutions enabling Scientific use of content for the application of text and data mining tools. For example, according to the amendment of the Act on Copyright and Related Rights, the Act on the Protection of Databases, and the Act on Collective Management of Copyright and Related Rights, which came into force on September 20, 2024, and implements the Directive on Copyright in the Digital Single Market1, there is a possibility to use protected works for text and data mining:
Info
1. Cultural heritage institutions, as well as entities referred to in Art. 7, para. 1, points 1, 2, and 4–8 of the Act of July 20, 2018 – Law on Higher Education and Science, may reproduce works for text and data mining for scientific research purposes, provided that these activities are not carried out for direct or indirect financial gain.
2. Works reproduced in accordance with para. 1 may be stored for scientific research purposes, including verification of the research results. Storage of the works is conducted with a level of security ensuring access to these works only to authorized persons, taking into account authentication procedures.
3. The authorized party, in order to ensure the security and integrity of the networks and databases in which the works are stored, may use only the measures necessary to achieve this goal.
An analogous solution has been adopted regarding the use of databases:
Info
1. Cultural heritage institutions, as well as entities referred to in Art. 7, para. 1, points 1, 2, and 4–8 of the Act of July 20, 2018 – Law on Higher Education and Science, may reproduce databases for text and data mining for scientific research purposes, provided that these activities are not carried out for direct or indirect financial gain.
2. Databases replicated in accordance with paragraph 1 may be stored for the purposes of scientific research, including verification of the results of such research. Databases shall be stored at a level of security that ensures access only to authorized persons, taking into account authentication procedures.
3. In order to ensure the security and integrity of the networks and databases in which the works are stored, the rightholder may only use measures necessary to achieve this purpose.
The content of these regulations emphasizes that the use of works and databases for text and data mining must be strictly related to scientific, not commercial, objectives. Researchers are obligated to ensure appropriate security for the stored data, including restricting access solely to authorized individuals.
- Secondly, the use of content generated by AI tools is problematic due to issues regarding who holds the rights to such content and under what conditions. The author of a copyrighted work can only be a human. Therefore, authorship cannot be attributed to algorithms, nor can one present themselves as the author of content that is solely generated by AI.
1 See discussion of relevant articles of the directive: Bagieńska-Masiota, A. (2022). Permitted Use for Text and Data Mining in Light of the Directive of the European Parliament and the Council (EU) 2019/790. Annales Universitatis Paedagogicae Cracoviensis | Studia De Cultura, 14(1), 118–128. DOI (PDF).