How can generative aI tools be used in research work?
What can scientists use generative AI for?
Here are some examples:
-
Writing and debugging code: generative AI can help write and improve code used for statistical analysis, creating data visualizations, or building websites that present research results.
-
Questioning assumptions: when working to formulate a research problem, scientists can cast generative AI as a critical debater, asking it to point out potential gaps in the research or help them think outside the box.
- Synthetic data generation: generative AI can create synthetic data that replicates the characteristics of real-world data, allowing you to enrich training sets or test methodologies before collecting expensive real-world data.
- Supporting literature reviews: with its natural language processing capabilities, generative AI can extract key information from scientific articles, such as relationships between variables, hypotheses, and data about the study sample. Properly constructed queries can reduce the risk of model hallucinations by limiting its answers to the content contained in the analyzed articles.
Apart from the typical applications of generative AI tools, there are two main ways in which they can be used in research:
-
Generative AI as a text processing tool: covers tasks such as classification, Named Entity Recognition, information retrieval, and ambiguity resolution.
-
Generative AI for process automation and personalization of research tools: streamlines research processes and enables customization of tools to the individual needs of the researcher.
Generative AI as a text processing tool
Generative AI represents an advancement from "pre-generative" natural language processing (NLP) methods and can be utilized for text classification. Liga and Robaldo (2023) demonstrated that even models with relatively limited capabilities, such as GPT-3, when trained on specialized data, outperform previous NLP models in classifying legal texts based on the clauses they contain. Generative AI surpasses older methods especially in tasks that require understanding subtle semantic nuances. However, for classification based on the presence of specific keywords, traditional classification algorithms, with appropriate training datasets, remain sufficient.
Interestingly, even in tasks that do not require understanding complex context, such as Named Entity Recognition (NER)—which involves recognizing specific entities in a text, like protein or gene names—generative AI matches, and often exceeds, the effectiveness of previous NLP models. The older GPT-3 model achieved results comparable to fully supervised NER models (Wang et al., 2023). The usefulness of large language models has also been demonstrated in NER applications for analyzing texts in the field of astronomy (Shao et al., 2023).
Large language models (LLM) can also be successfully used for disambiguation tasks. For instance, LLMs can analyze unstructured online profiles of individuals sharing the same names (Sancheti et al., 2024).
A key component of LLMs is embedding models, which allow for encoding information about the meaning of textual entities—from individual tokens to sentences and entire texts. Embeddings are multidimensional vectors, enabling algebraic operations and determining relationships between them, including similarities. More advanced embedding models, which capture semantic nuances more effectively thanks to a larger number of dimensions, will play a crucial role in automating analytical work, allowing for more precise inference and analysis.
An example of the application of embedding models is the creation of crosswalks between different classifications. In labor market economics, crosswalks between the American ONET-SOC classification and the European ISCO are often used. Traditionally, this process is time-consuming, requires detailed attention, rule creation, and is costly as it needs to be repeated with each database update. Currently, embedding models enable effective classification matching based only on job titles, and enriching the model with additional context, such as tasks or job descriptions, allows for even more precise matching.
A characteristic feature of the mentioned applications is the limitation of the generative functions of LLM and reliance on knowledge from specific sources provided by the researcher (such as a set of scientific articles), instead of the knowledge from the model's original training. Generative functions refer to the model's ability to create new content without referencing specific sources. Limiting these functions aims to minimize the problem of so-called hallucination, that is, generating incorrect or non-existent information.
The advantage of LLM in research work, as evidenced by both our experiences and the literature review, is primarily the ability of these models to understand natural language in the context of the text provided by the researcher. Often, though not always, this is possible due to fine-tuning, which involves adjusting a pre-trained model to specific tasks or thematic areas through additional training on smaller, dedicated datasets. This allows the model to better handle tasks requiring specialized knowledge.
Another advantage of applying LLM is lowering the entry barrier to NLP analysis, as researchers can increasingly use LLM models in zero-shot mode, meaning without the need for training datasets. Despite lacking specialized knowledge in NLP and without the need to acquire or create dedicated datasets, it is possible to achieve results comparable to those obtained with more advanced methods.
Generative AI for process automation and personalization of research tools
The second application of generative AI in research goes beyond replacing older NLP models. In this approach, generative AI is used to partially automate research processes and personalize research tools.
The fact that LLMs are trained on, among other things, scientific literature has prompted many researchers to explore their potential for creating literature reviews. Scientists have begun to test the models’ knowledge in areas they know well and use them to automate literature reviews in areas they had no previous experience with. To their surprise, the models often “hallucinate,” creating nonexistent scientific papers, supposedly authored by well-known researchers, with convincing-sounding titles. Although these errors result from the LLM training process and their misuse, the lack of appropriate information policies or the ability to block the generation of false references, such as blocking discriminatory content, lowers scientists’ confidence in using LLMs in research.
In response to the shortcomings of general LLM tools in scientific literature review, specialized models are being developed. These models are based on collections of scientific articles that are structured using LLM tools, such as identifying hypotheses, results, and other key elements. Language models are then fine-tuned to this data, and special prompts are developed to efficiently extract information from texts (Cao et al., 2024). This approach allows models not only to better understand the content of articles, but also to provide the context in which authors obtained specific results and indicate whether these results confirm or refute a given hypothesis. As a result, specialized LLM models become much more efficient and precise in scientific literature review (Nicholson et al., 2021).
The best LLMs for literature reviews are often expensive (for example, scite_ costs institutions around $5000 annually, while students and individual researchers pay about 50 PLN per month). This is due to the high costs associated with training them and creating databases that rely on millions of articles, often behind paywalls. However, it's worth noting that the development of these advanced models somewhat contradicts the idea of open science and the democratization of knowledge. Limited access to the most advanced tools may hinder the dissemination of knowledge and conflict with the premises of the open science model.
The development of models for literature reviews limits the problem of hallucinations, although there is still the challenge of their functioning as so-called black boxes. It's possible that the movement for explainable AI will contribute to greater transparency in the selection of literature and evaluation criteria (Xu et al., 2019). For now, we recommend treating these tools solely as support in the literature review process, rather than its main foundation.
On the other hand, LLM tools are useful in analyzing articles selected in a traditional literature review based on keywords. Preliminary results of studies conducted by DELab UW within the IDUB UW project indicate the effectiveness of LLMs in structuring information from scientific articles, which supports conducting systematic literature reviews and meta-analyses.
The reproduction of a meta-analysis published in a prestigious journal demonstrated the superiority of a text mining tool created by DELab UW and based on the GPT-4 model over the work of human annotators. In cases of discrepancies between the model's results and those of humans, the model's advantage likely resulted from heuristics applied by human assistants when analyzing large collections of articles. The task involved extracting information regarding the research samples, main results, hypotheses, etc. The text mining tool better identified, among other things, the sample size utilized in the analysis.
Preliminary results indicate that LLM tools have significant potential in time-consuming processes, such as preparing data for meta-analyses. They enable these tasks to be carried out more cost-effectively, eliminating the need to train research assistants for text annotation and instead engaging them in evaluating the quality of the model's work. A key advantage of LLM models is their scalability, which allows them to analyze a much larger number of texts than a human can, thus enabling a broader range of literature to be included in research.
An example of personalizing research tools is the work by Paliński et al. (in preparation), in which the authors used the GPT-3.5 model to create personalized advertisements in a study on consumer privacy preferences in the context of streaming services. The authors developed a tool resembling a popular streaming application, with which respondents interacted. The collected data was then used in prompts to the GPT-3.5 model, which generated personalized advertisement content displayed to participants in the form of animations.
Fig. Scheme of creating a research tool based on LLM - personalization of advertisements displayed to respondents in the study of preferences for personalization.
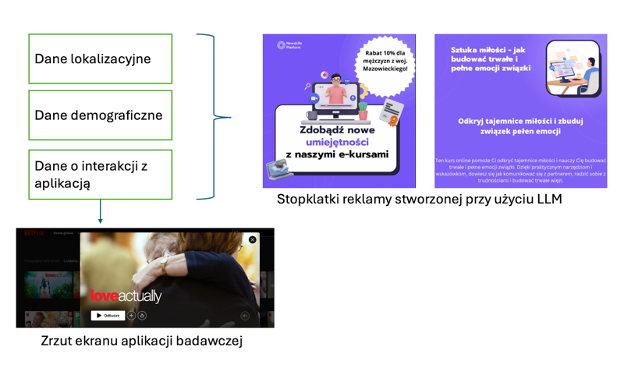
Source: Paliński et al. (in preparation).
References:
Cao, C., Yuan, Z., & Chen, H. (2024). ScholarGPT: Fine-tuning Large Language Models for Discipline-Specific Academic Paper Writing.
Liga, D., & Robaldo, L. (2023). Fine-tuning GPT-3 for legal rule classification. Computer Law & Security Review, 51, 105864.
Nicholson, J. M., Mordaunt, M., Lopez, P., Uppala, A., Rosati, D., Rodrigues, N. P., ... & Rife, S. C. (2021). scite: A smart citation index that displays the context of citations and classifies their intent using deep learning. Quantitative Science Studies, 2(3), 882-898.
Paliński, M., Jusypenko, B., Hardy, W. (w przygotowaniu). Behind the Screens. Privacy concerns and persuasion knowledge as determinants of preferences for privacy and advertising on Netflix.
Sancheti, P., Karlapalem, K., & Vemuri, K. (2024). LLM Driven Web Profile Extraction for Identical Names. In Companion Proceedings of the ACM on Web Conference 2024 (pp. 1616-1625).
Shao, W., Hu, Y., Ji, P., Yan, X., Fan, D., & Zhang, R. (2023). Prompt-NER: Zero-shot named entity recognition in astronomy literature via large language models. arXiv preprint arXiv:2310.17892.
Wang, Shuang, Xiaoxu Sun, Xin Li, Renjie Ouyang, Fangxiang Wu, Tingting Zhang, and Guoxin Wang. (2023). “GPT-NER: Named Entity Recognition via Large Language Models.” arXiv preprint arXiv:2304.10428.
Xu, Feiyu, et al. "Explainable AI: A brief survey on history, research areas, approaches and challenges." Natural language processing and Chinese computing: 8th cCF international conference, NLPCC 2019, dunhuang, China, October 9–14, 2019, proceedings, part II 8. Springer International Publishing, 2019.
Zhou, Wenxuan, Sheng Zhang, Yu Gu, Muhao Chen, and Hoifung Poon. (2023). “Universalner: Targeted Distillation from Large Language Models for Open Named Entity Recognition.” arXiv preprint arXiv:2308.03279.